Channel Tracing and Attribution
This tutorial demonstrates how to identify which feature channels contribute most to a specific segment produced by k-way Normalized Cuts (NCUT). We adopt a gradient-based attribution method (similar to Grad-CAM) to rank the importance of feature channels.
Quick Start
Here is a minimal example showing how to compute gradients of the eigenvectors with respect to the input features.
from ncut_pytorch import Ncut
import torch
# 1. Prepare features with gradient tracking
# features: (H, W, feature_dimension)
features = torch.randn(100, 100, 300)
features.requires_grad = True
features_2d = features.view(-1, features.shape[-1]) # (H*W, feature_dimension)
# 2. Compute NCUT with gradient tracking enabled
n_eig = 20
eigvecs = Ncut(n_eig=n_eig, exact_gradient=True, device='cuda').fit_transform(features_2d)
# 3. Define a loss and backpropagate
# Here we simply use the sum of eigenvectors as a dummy loss
loss = eigvecs.sum()
loss.backward()
# 4. Access gradients
grad = features.grad # (H, W, feature_dimension)
# 5. Identify top-k influential channels
k = 10
# Rank channels by mean absolute gradient magnitude
topk_vals, topk_idx = grad.abs().mean(dim=(0, 1)).topk(k)
print("Top-k feature indices:", topk_idx)
Examples
Below are examples of channel tracing results visualized.
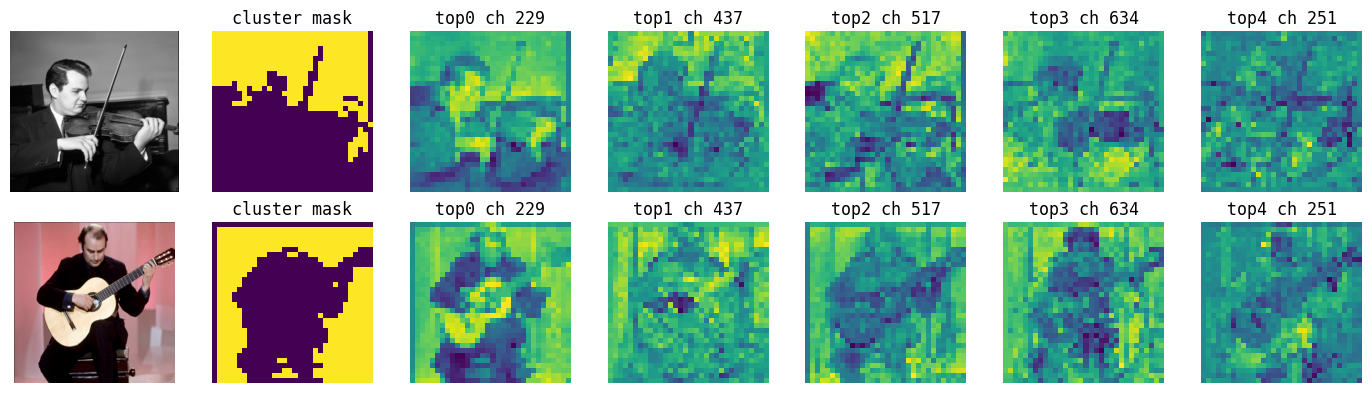

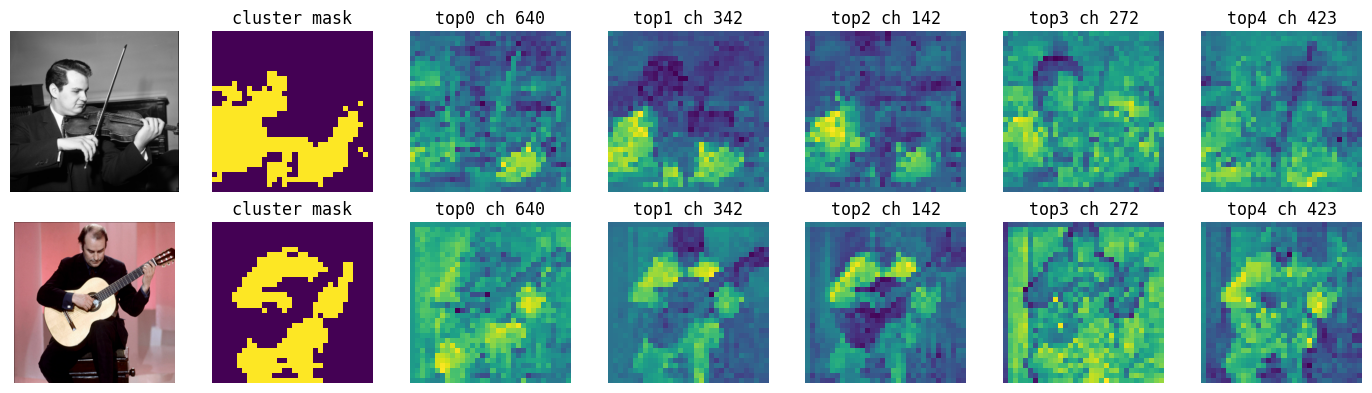
Methodology
To trace which feature channels are most responsible for a specific cluster, we follow these steps:
- Cluster Assignment: Perform k-way NCUT to obtain soft cluster scores and assign each pixel to a cluster (hard assignment).
- Objective Definition: Define a scalar objective for a target cluster. A common choice is the average absolute cluster score for pixels assigned to that cluster.
- Backpropagation: Backpropagate this objective to the input features. This yields a gradient map indicating how each channel at each pixel affects the confidence of the target cluster.
- Aggregation: Aggregate the gradients within the target cluster's region (e.g., by averaging) to obtain a single importance score per channel.
- Ranking: Rank channels by their importance scores to identify the most influential ones.
Implementation Details
Setup and Feature Extraction
First, we set up the environment and define helpers for feature extraction.
from einops import rearrange
import torch
from PIL import Image
from ncut_pytorch import Ncut, kway_ncut
# Helper to load images
def load_images_helper(pil_images_or_paths):
if isinstance(pil_images_or_paths[0], str):
pil_images = [Image.open(p) for p in pil_images_or_paths]
else:
pil_images = pil_images_or_paths
pil_images = [im.convert("RGB") for im in pil_images]
return pil_images
# Helper to prepare features (example using DINO)
# dino_img_transform(image) -> tensor
# extract_dino_image_embeds(batch) -> [B, L+1, C]
def prepare_grid_features(images, dino_img_transform, extract_dino_image_embeds):
images_tensor = torch.stack([dino_img_transform(im) for im in images])
dino_embeds = extract_dino_image_embeds(images_tensor)[:, 1:, :] # Drop CLS token -> [B, L, C]
b, l, c = dino_embeds.shape
h = w = int(l ** 0.5)
features = rearrange(dino_embeds, 'b l c -> (b l) c') # [(B*H*W), C]
return features, b, h, w
Differentiable k-way NCUT
Next, we run the differentiable NCUT to obtain the eigenvectors and k-way discretization.
def differentiable_kway_ncut(features, n_segment):
assert features.requires_grad is True
# Use the exact eigensolver path when gradients matter
eigvec = Ncut(n_eig=n_segment, exact_gradient=True).fit_transform(features)
# Discretize eigenvectors to get soft cluster assignments
kway_eigvec = kway_ncut(eigvec) # shape: [(B*H*W), K]
return eigvec, kway_eigvec
# Usage
features = features.clone().requires_grad_(True)
eigvec, kway_eigvec = differentiable_kway_ncut(features, n_segment=4)
Channel Attribution per Cluster
We calculate the gradient of the cluster score with respect to the input features.
def channel_gradient_from_cluster(features, cluster_mask, kway_eigvec, cluster_idx):
"""
Computes the average gradient per channel for a given cluster.
Args:
features (torch.Tensor): Input features with requires_grad=True.
cluster_mask (torch.Tensor): Boolean mask for the target cluster.
kway_eigvec (torch.Tensor): Soft cluster assignments.
cluster_idx (int): Index of the target cluster.
Returns:
torch.Tensor: Gradient magnitude per channel (shape [C]).
"""
assert features.requires_grad is True
if features.grad is not None:
features.grad.zero_()
# Define loss: Negative average absolute score of the cluster
# We want to maximize the score, so we minimize the negative
loss = - kway_eigvec[cluster_mask, cluster_idx].abs().mean()
# Backpropagate
loss.backward(retain_graph=True)
# Aggregate gradients over the cluster region
grad = features.grad[cluster_mask].mean(0) # [C]
return grad
Execution and Ranking
Finally, we iterate over clusters to compute channel importance.
# Derive hard assignments
cluster_assign = kway_eigvec.argmax(1) # [(B*H*W)]
all_cluster_grads = []
for k in range(kway_eigvec.shape[1]):
mask_k = (cluster_assign == k).detach().cpu()
if mask_k.sum() == 0:
continue
grad_k = channel_gradient_from_cluster(features, mask_k, kway_eigvec, k)
all_cluster_grads.append(grad_k)
Visualization Helpers
import numpy as np
def rank_channels(grad, descending=True):
"""Rank channels by value."""
return torch.argsort(grad, descending=descending)
def reshape_for_view(features, b, h, w):
"""Reshape flattened features back to (B, H, W, C)."""
return features.detach().reshape(b, h, w, -1).cpu().numpy()
def extract_topk_maps(feature_grid, channel_indices, image_index=0, topk=5):
"""Extract feature maps for the top-k channels."""
# feature_grid: [B, H, W, C] ndarray
chs = channel_indices[:topk].tolist()
maps = [feature_grid[image_index, :, :, ch] for ch in chs]
return chs, maps